英文文本分词之工具NLTK
文文本分词之工具NLTK
安装NLTK
1 | |
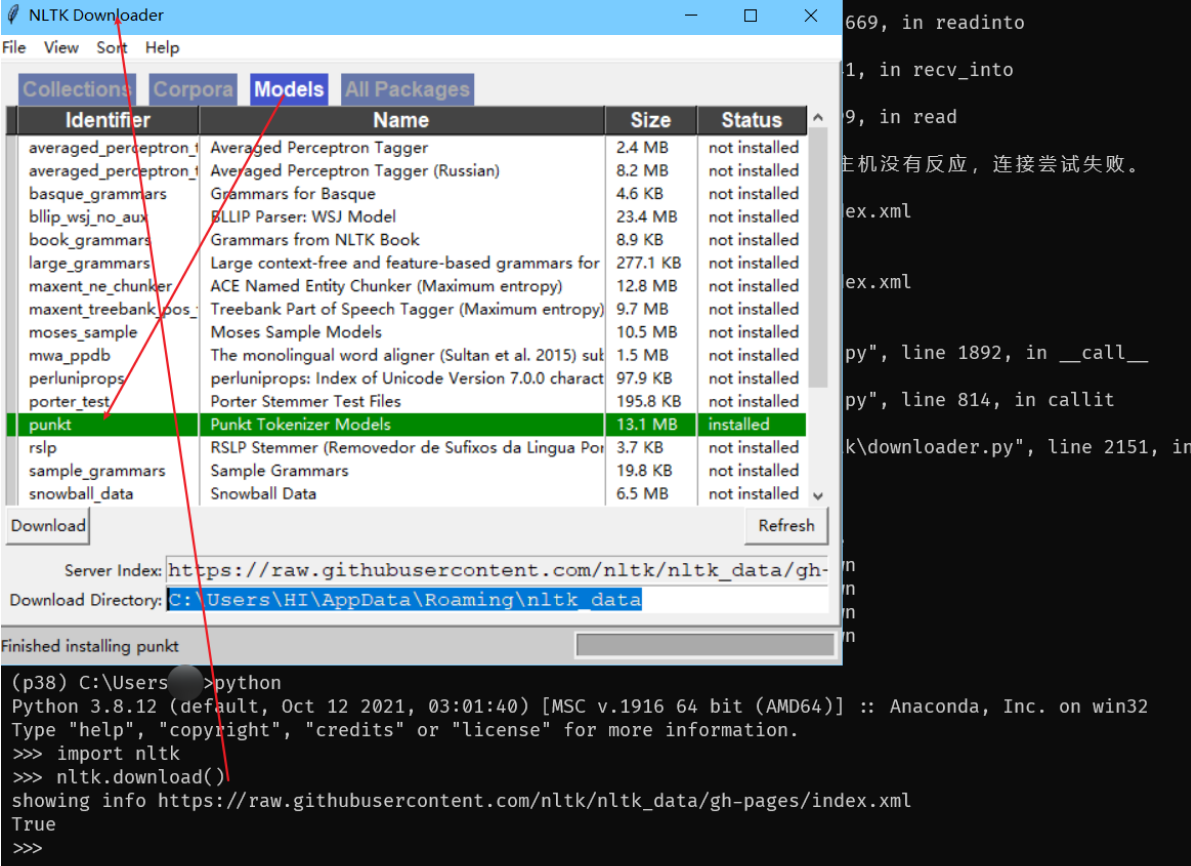
分词需要用到两个包:stopwords和punkt,需要下载:
1 | |
如果你能运行成功,那么恭喜,但多半要和我一样,被墙,然后下载失败。于是乎,需要手动下载,这里我已经打包好了,百度提取即可。
1 | |
此处也是要感激广大网友的无私分享和帮助!!!
停用词和标点符号包放置
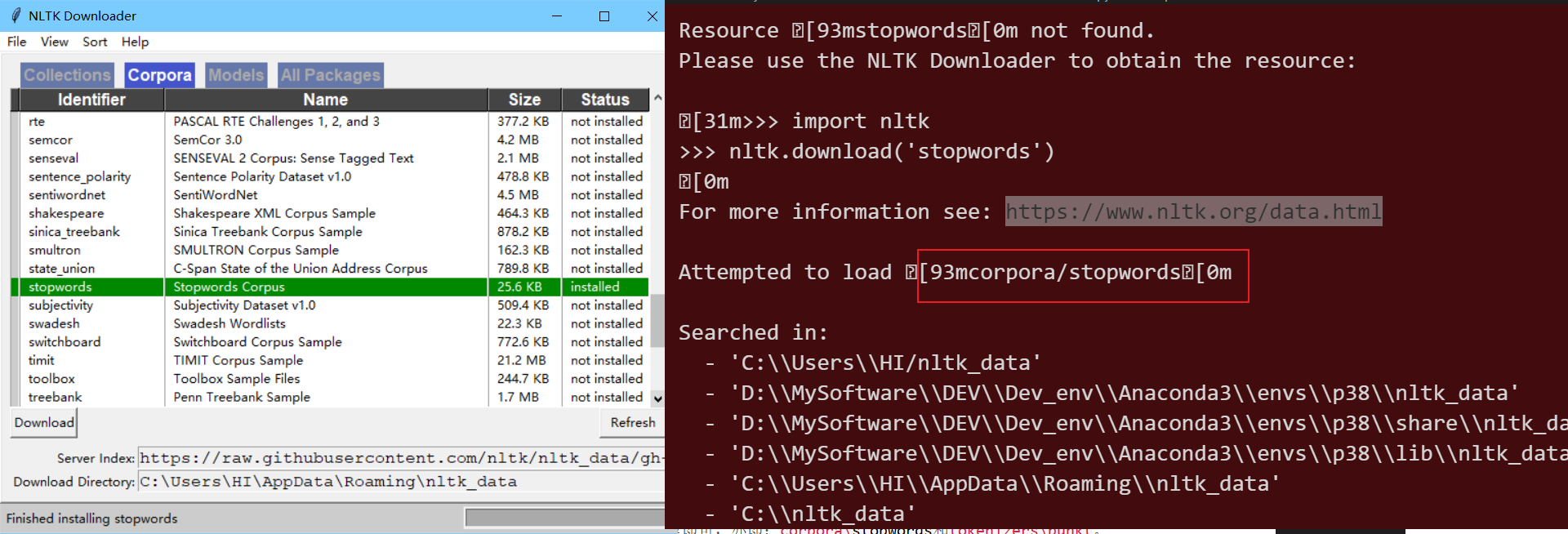
言归正传,下载解压后要注意,stopwords里面还有个stopwords文件,punkt文件里面还有个punkt文件,我们需要的是里面的这两个文件,而不是最外围的同名文件,虽然包含的内容一样,但是python读取的时候路径会出错。将里面的stopwords和punkt文件夹分别移动到python安装目录下的两个子路径中,比如我的路径是F:\python38\Lib\nltk_data\corpora和F:\python38\Lib\nltk_data\tokenizers。需要说明的是,我的F:\python38\Lib路径下并没有nltk_data这个文件,没有?没有就让他有!新建文件夹,重命名即可。
然后在nltk_data中再新建两个文件夹:corpora和tokenizers。然后把停用词和标点分别移动到这两个文件里即可,亦即:corpora\stopwords和tokenizers\punkt。
验证
此处提供一段验证代码,明日开始nltk分词之旅!
1 | |
完结,可以愉快地听歌了。
英文文本分词之工具NLTK
http://example.com/2021/11/18/英文文本分词之工具NLTK/